MapReduce - Let's average numbers
In the big data context, MapReduce plays a significant role. It is the underlying techniques for most of the big data frameworks- like apache hadoop, spark + many more platforms. In this article we are not going to learn MapReduce but solving a big data problem.
Recently I wanted to average numbers in huge data set. For an example lets say I have numbers like,
So this might be a big data set with TBs of data, and we can’t process it in a single machine. So how we solve this big data problem as simple as possible?
The dumbest solution (but working!)
The simplest way is to map each number to a single key like (1,x) here x represents the numbers in the data set. So all
the numbers will be loaded to one key and reducer will reduce them all. This approach is not really using the benefits of
the MapReduce framework. This is more like an overhead to the simple looping averaging algorithm.
So we have to find a trick to distribute the data set across multiple keys.
A better solution
Here we are going to distribute map the dataset across multiple keys and reduce with multiple
reducers.
Here is the flow diagram.
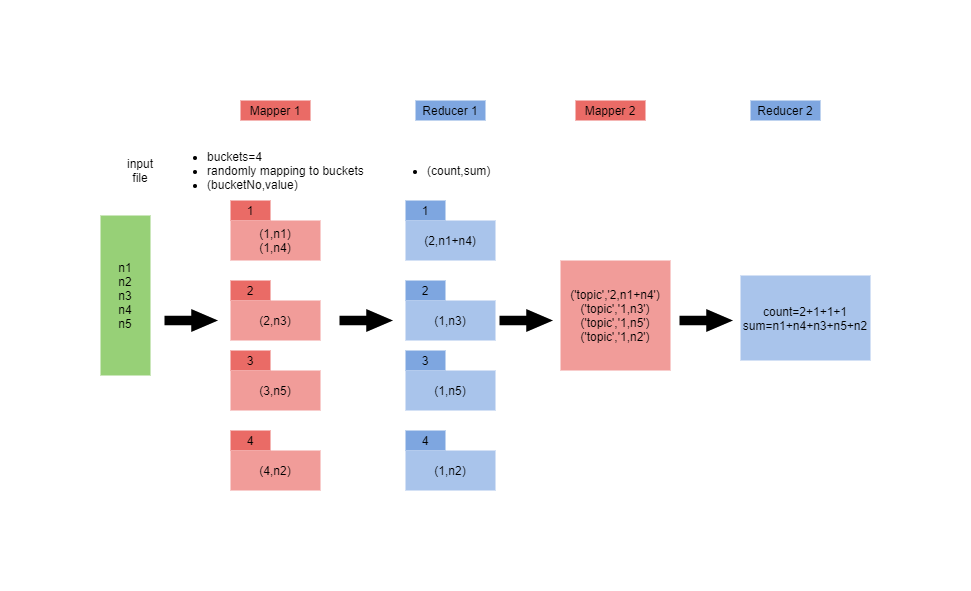
This way going to use two MapReducers by chaining.
Let’s go to implementation. Find the full code here
Phase 1 Mapper
In this case we get (line no, number) as the (K,V) but number is the only thing important to us. To distribute these numbers
we randomly assign those numbers into buckets (here we have 4 buckets). In other words, bucket no means the key for that data point.
So in this example we have 4 keys. Therefore, (K1,list(numbers)),...,(K4,list(numbers)) will be received at reducer phase.
Phase 1 Reducer
Here we accumulate the numbers and find the sum and count. So the PrimaryReduce will return (count,sum) as (K,V). These
results will be saved to the file system temporarily and that is a disadvantage with multiple job chaining.
Phase 2 Mapper
Now we need to get all the data to one single key, so we can average easily. Simple. Just look at the code.
Phase 2 Reducer
Now key="one" will get all the sum,count so we run averaging function adding total and count to get the final total and final count.
Average is simply sum/count and we output as ("output",average) so this result will be saved again in the HDFS.
Now chain all the functions as in Average.java
Let’s test on AWS EMR cluster.
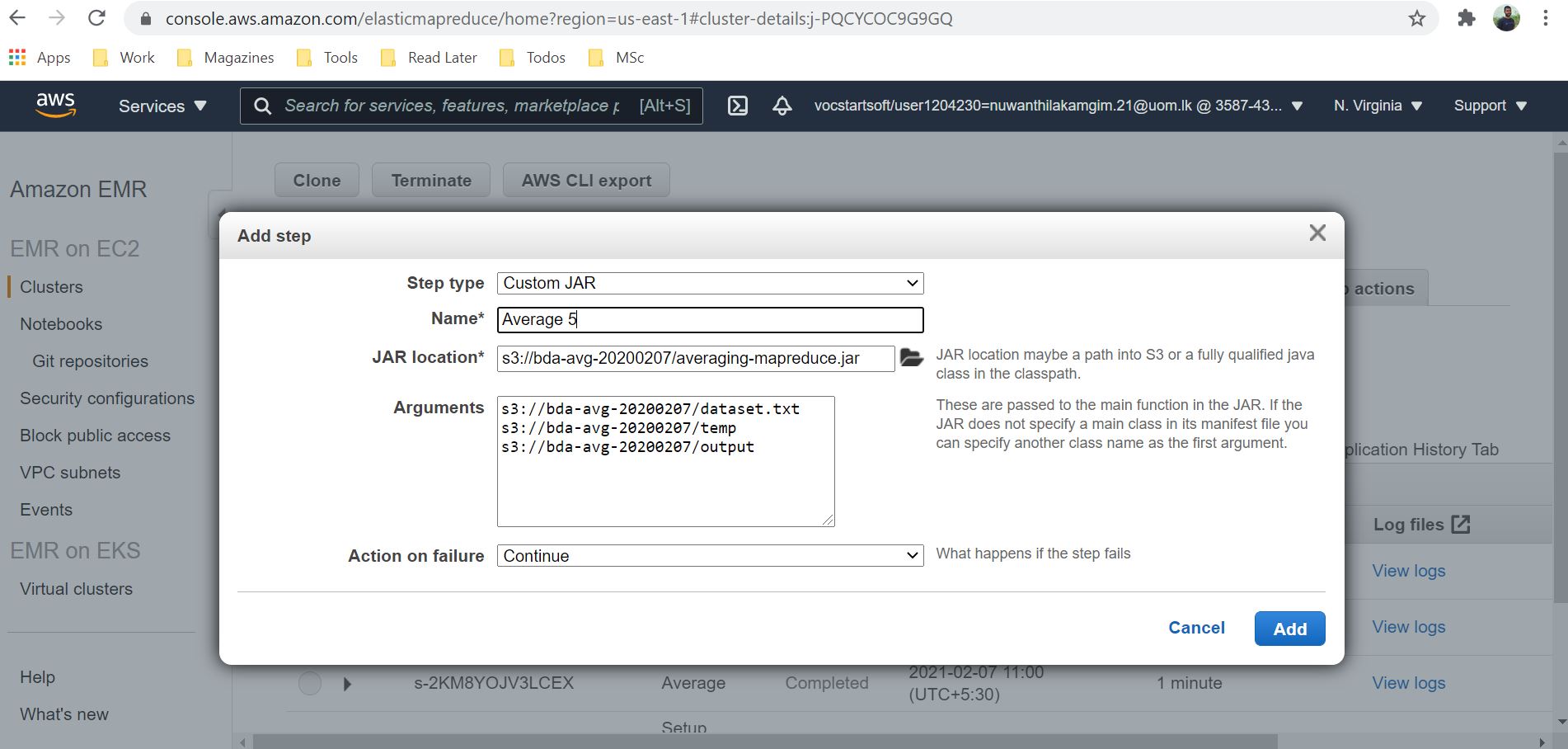
Once the step is completed successfully check the /output folder in S3 for results.
Happy Coding!