Understanding Compilers from scratch
Technologies are evolving so fast. New programming languages rising up while legacy programming languages are improving and going deeper. Last year I came across with new language — Ballerina, a open source programming language — which grabbed my attention in the first sight. After testing few sample code I wanted to learn how it is built, so as the first step I tried learning its compiler design.
So in this article we are going to learn some key concepts and build a small compiler program, not a complete solution but a simple application which will translate assembly like small new language to machine code which can be fed into a processor designed on Altera FPGA.
What is compiler?
A program that translate a program from source language into a target language. In Ballerina, it is from Ballerina source code to a bytecode which fed to machine later. Source code is in high level programming language like C/Java then Compiler will translate them to assembly code latter MIPS assembler will convert bytecode into machine code.
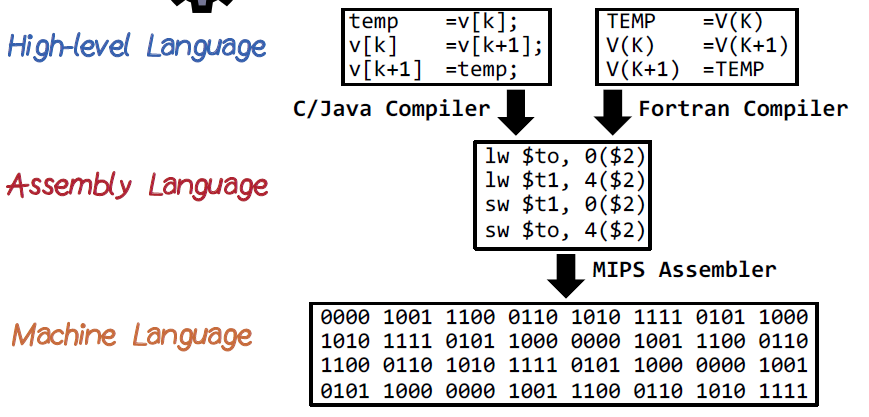
Compiler Parts
Compilers consist three main parts.
-
Front-end
-
Middle ware
-
Back-end
Front-end works with the higher level programming language and does main analysis to identify whether the source code is in a good heath to be translated. So it carries three analysis.
-
Lexical Analysis
-
Syntactical Analysis
-
Semantic Analysis
Middle ware concern about preparing the intermediate representation of the code and its optimization In the back-end, the real translation happens. Well it has two main components.
-
Code generation
-
Optimization
so lets talk about how really the compiler does all these work.
How compiler works
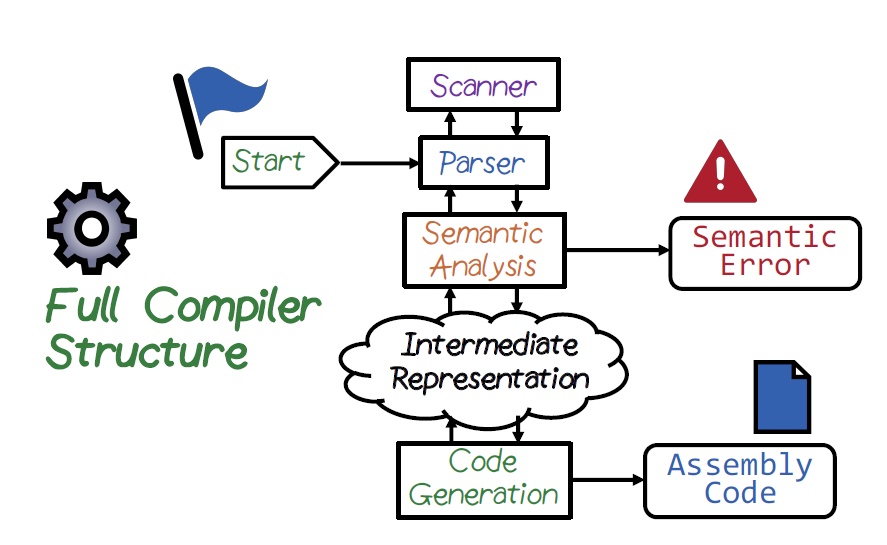
Above illustration shows the whole work done in a compiler.Lets break into small pieces and talk.
Scanner
This component scans the source code and generate tokens. Its main responsibility is to read character by character and load it to token buffer and generate tokens according to the lexical rules. Lexical rules are the criterion about how the language is declared. For a example variable names should not start with a underscore (like _var is illegal). Scanner will work on Maximum Length algorithm so it will tokenize a maximum length word. Then this tokens will be sen to Parser. Lexical rules are defined using Regular expressions which we are not going to talk about here.
Parser
Parser will do two main analysis ; Syntactical analysis and Sentiment analysis. After parser gets a token from the tokenizer then it looks for the symbol tables to do the other analysis. Syntactical analysis check whether the grammar of the sentence is correct. A design of the grammar should be done properly to remove syntactical ambiguity. For a example,
public class Main {
public static void main(String[] args) {
System.out.println("This will be printed") // should be ; at the end of the statement
}
}
Here,according java grammar every statement should end with semicolon(;) but it is missing so the parser will raise syntax error.
Lets understand semantic analysis. sometimes grammar can be correct but it can be incorrect in terms of the context. There is a catch here — we don’t do semantic analysis because it is very costly and need extra work, so first syntax is checked then only semantic analysis done. This way we can reduce the workload.
public class Main {
public static void main(String[] args) {
int a;
int b;
c = a + b;
System.out.println(c);
}
}
Here grammar can be correct but variable c is not defined so it is not available in this context. So this raises a semantic error.
If everything is okay then the healthy code is translated into intermediate representation (not the bytecode) only to support translation. This will a simpler version of the source code. Example,
d = a + b + c
//this will be translated to
temp = a + b
d = temp + c
After this phase, assembly code will be generated and some optimizations will be there.
For a example lets do a simple code translation.
This will be a small assembler
This small language is designed for a image down sampling project. Lets look the source code for adding two numbers.
//loading 1 to R6
SWAPA:R12,R14
LOAD:R6,R12
SWAPA:R12,R14
//Loadding 4 to R7
SWAPA:R12,R16
LOAD:R7,R12
SWAPA:R12,R16
//Adding
MOVY:R1,R6
ADD:R1,R7
MOVB:R5,R2
COMOs
Assembler coded in python.
##compiler for custom ISA
#define input and output files
inputfile='add.txt'
outputfile='add.coe'
##initial addresses
memory_count=0
address={
'R1':"0",
'R2':"1",
'R11':"0",
'R12':"1",
'R3':"000",
'R4':"001",
'R5':"010",
'R6':"011",
'R7':"100",
'R8':"101",
'R9':"110",
'R10':"111",
'R':"000",
'R13':"001",
'R14':"010",
'R15':"011",
'R16':"100",
'R17':"101",
'R18':"110",
'R19':"110",
}
step={}
##reading from finput ile
with open(inputfile,'r') as fo:
file=fo.read()
file=file.split('\n')
##removing empty lines
f=[]
for i in file:
if len(i)>0:
f.append(i)
file=f
#detecting step labels
temp=0
for line in range(len(file)):
words=file[line].split(':')
if any(words[0][i:] in ['NOP','LOAD','STR','MOVB','MOVY','ADD','SUB','INCA','MUL','DIV','CLEAR','COMI','COMO','SWAPA'] for i in range(0,len(words[0]),4)):
temp+=1
elif any(words[0][i:] in ['JMPZ','JMPNZ'] for i in range(0,len(words[0]),4)):
temp+=2
elif any(words[0][i:len(words[0])-1]=='step' for i in range(0,len(words[0]),4)):
step[words[0][-5:]]=memory_count+temp
##adding binary codes
file1=[]
for line in range(len(file)):
words=file[line].split(':')
if any(words[0][i:]=='NOP' for i in range(0,len(words[0]),4)):
file1.append("00000000,")
elif any(words[0][i:]=='LOAD' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("0001"+address[temp[1]]+address[temp[0]]+",")
elif any(words[0][i:]=='STR' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("0010"+address[temp[0]]+address[temp[1]]+",")
elif any(words[0][i:]=='MOVB' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("0011"+address[temp[1]]+address[temp[0]]+",")
elif any(words[0][i:]=='MOVY' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("0100"+address[temp[0]]+address[temp[1]]+",")
elif any(words[0][i:]=='JMPZ' for i in range(0,len(words[0]),4)):
file1.append("01010000"+",")
file1.append('{0:08b}'.format(step[words[1]])+",")
elif any(words[0][i:]=='JMPNZ' for i in range(0,len(words[0]),4)):
file1.append("01100000"+",")
file1.append('{0:08b}'.format(step[words[1]])+",")
elif any(words[0][i:]=='ADD' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("0111"+address[temp[0]]+address[temp[1]]+",")
elif any(words[0][i:]=='SUB' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("1000"+address[temp[0]]+address[temp[1]]+",")
elif any(words[0][i:]=='INCA' for i in range(0,len(words[0]),4)):
file1.append("1001"+address[words[1]]+"000,")
elif any(words[0][i:]=='MUL' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("1010"+address[temp[0]]+address[temp[1]]+",")
elif any(words[0][i:]=='DIV' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("1011"+address[temp[0]]+address[temp[1]]+",")
elif any(words[0][i:]=='CLEAR' for i in range(0,len(words[0]),4)):
file1.append("11000"+address[words[1]]+",")
elif any(words[0][i:]=='COMI' for i in range(0,len(words[0]),4)):
file1.append("11010000,")
elif any(words[0][i:]=='COMO' for i in range(0,len(words[0]),4)):
file1.append("11100000,")
elif any(words[0][i:]=='SWAPA' for i in range(0,len(words[0]),4)):
temp=words[1].split(',')
file1.append("1111"+address[temp[0]]+address[temp[1]]+",")
file=file1
file.insert(0,'MEMORY_INITIALIZATION_RADIX=2;')
file.insert(1,'MEMORY_INITIALIZATION_VECTOR=')
file[-1]=file[-1][:-1]+';'
##writing to output file
with open(outputfile,'w') as fo:
n=len(file)
for i in range(n):
if i!=n-1:
fo.write(file[i]+'\n')
else:
fo.write(file[i])
Usage of the programming language.
|----------------------------------------------------------------------------|
|INSTRUCIONS OPCODES |
|----------------------------------------------------------------------------|
|NOP - 0000 |
|LOAD:(R3-R10),(R11/R12) - 0001 |
|STR:(R11/R12),(R3-R10) - 0010 |
|MOVB:(R3-R10),(R1/R2) - 0011 |
|MOVY:(R1/R2),(R3-R10) - 0100 |
|JMPZ:step1(just a label starting with 'step' ) - 0101 |
|JMPNZ:step1 - 0110 |
|ADD:(R1/R2),(R3-R10) - 0111 |
|SUB:(R1/R2),(R3-R10) - 1000 |
|INCA:(R11/R12) - 1001 |
|MUL:(R1/R2),(R3-R10) - 1010 |
|DIV:(R1/R2),(R3-R10) - 1011 |
|CLEAR:(R3-R10) - 1100 |
|COMI - 1101 |
|COMO - 1110 |
|SWAPA:(R11/R12),(R,R13-R19) //R for R8,R9,R10 - 1111 |
|----------------------------------------------------------------------------|
|STORED NUMBERS |
|----------------------------------------------------------------------------|
|R13 has number 0 |
|R14 has number 1 |
|R15 has number 255 |
|R16 has number 4 |
|R17 has number 8 |
|R18 has number 16 |
|R19 has number 7 |
|----------------------------------------------------------------------------|
|R1-0,R2-1 |
|R11-0,R12-1 |
|R3-000,R4-001,R5-010,R6-011,R7-100,R8-101,R9-110,R10-111 |
|----------------------------------------------------------------------------|
Resources
-
https://github.com/isurunuwanthilaka/Image-Down-Sampling-Custom-Processor
-
https://medium.com/@sameerajayasoma/ballerina-compiler-design-3406acc2476c
The End
This is very simple , but, will ease your life a lot. Hope you enjoyed.
Happy Coding!